一、源码目录设计、编译
Flow
facebook 出品的 JavaScript 静态类型检查工具。类型检查是当前动态类型语言的发展趋势,所谓类型检查,就是在编译期尽早发现(由类型错误引起的)bug,又不影响代码运行(不需要运行时动态检查类型),使编写 JavaScript 具有和编写 Java 等强类型语言相近的体验。
- 类型推断:通过变量的使用上下文来推断出变量类型,然后根据这些推断来检查类型。
- 类型注释:事先注释好我们期待的类型,Flow 会基于这些注释来判断。
源码目录设计
1 | src |
- compiler
包括把模板解析成 ast 语法树,ast 语法树优化,代码生成等功能。编译的工作可以在构建时做(借助 webpack、vue-loader 等辅助插件);也可以在运行时做,使用包含构建功能的 Vue.js。
- core
包括内置组件、全局 API 封装、Vue 实例化、观察者、虚拟 DOM、工具函数等。
- platform
是 Vue.js 的入口,2 个目录代表 2 个主要入口,分别打包成运行在 web 上和 weex 上的 Vue.js。
- server
所有服务端渲染相关的逻辑都在这个目录下。服务端渲染主要的工作是把组件渲染为服务器端的 HTML 字符串,将它们直接发送到浏览器,最后将静态标记”混合”为客户端上完全交互的应用程序。
- sfc
把 .vue 文件内容解析成一个 JavaScript 的对象。
- shared
定义一些工具方法,这里定义的工具方法都是会被浏览器端的 Vue.js 和服务端的 Vue.js 所共享的。
源码构建
1 | { |
scripts/build.js
1 | let builds = require('./config').getAllBuilds() |
scripts/config.js
1 | const builds = { |
对于单个配置,它是遵循 Rollup 的构建规则的。其中 entry 属性表示构建的入口 JS 文件地址,dest 属性表示构建后的 JS 文件地址。format 属性表示构建的格式,cjs 表示构建出来的文件遵循 CommonJS 规范,es 表示构建出来的文件遵循 ES Module 规范。 umd 表示构建出来的文件遵循 UMD 规范。
scripts/alias
1 | const path = require('path') |
- Runtime Only
我们在使用 Runtime Only 版本的 Vue.js 的时候,通常需要借助如 webpack 的 vue-loader 工具把 .vue 文件编译成 JavaScript,因为是在编译阶段做的,所以它只包含运行时的 Vue.js 代码,因此代码体积也会更轻量。
- Runtime + Compiler
需要在客户端编译模板,编译过程对性能会有一定损耗。推荐使用 Runtime-Only。
Vue 的入口
import Vue from './runtime/index'
1 | import Vue from 'core/index' |
import Vue from 'core/index'
1 | import Vue from './instance/index' |
import Vue from './instance/index'
1 | import { initMixin } from './init' |
initGlobalAPI
src/core/global-api/index.js
1 | export function initGlobalAPI (Vue: GlobalAPI) { |
本质上就是一个用 Function 实现的 Class,然后它的原型 prototype 以及它本身都扩展了一系列的方法和属性。
二、数据驱动
1 | function Vue (options) { |
src/core/instance/init.js
1 | Vue.prototype._init = function (options?: Object) { |
Vue 初始化主要就干了几件事情,合并配置,初始化生命周期,初始化事件中心,初始化渲染,初始化 data、props、computed、watcher 等等。
Vue 实例挂载的实现
compiler 版本的 $mount 实现:
src/platform/web/entry-runtime-with-compiler.js
1 | const mount = Vue.prototype.$mount |
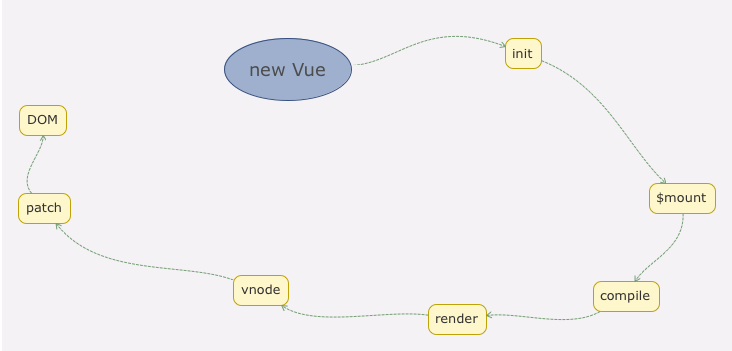
Vue 2.0 版本中,所有 Vue 的组件的渲染最终都需要 render 方法,无论我们是用单文件 .vue 方式开发组件,还是写了 el 或者 template 属性,最终都会转换成 render 方法,那么这个过程是 Vue 的一个“在线编译”的过程,它是调用 compileToFunctions 方法实现的,最后,调用原先原型上的 $mount 方法挂载。
$mount 方法:src/platform/web/runtime/index.js
1 | // public mount method |
$mount 方法支持传入 2 个参数,第一个是 el,它表示挂载的元素,可以是字符串,也可以是 DOM 对象,如果是字符串在浏览器环境下会调用 query 方法转换成 DOM 对象的。第二个参数是和服务端渲染相关,在浏览器环境下我们不需要传第二个参数。
mountComponentsrc/core/instance/lifecycle.js
1 | export function mountComponent ( |
mountComponent 核心就是先实例化一个渲染Watcher,在它的回调函数中会调用 updateComponent 方法,在此方法中调用 vm._render 方法先生成虚拟 Node,最终调用 vm._update 更新 DOM。最核心的 2 个方法:vm._render 和 vm._update。
Watcher 在这里起到两个作用,一个是初始化的时候会执行回调函数,另一个是当 vm 实例中的监测的数据发生变化的时候执行回调函数。
render
Vue 的 _render 方法是实例的一个私有方法,它用来把实例渲染成一个虚拟 Node。它的定义在 src/core/instance/render.js 文件中:
1 | Vue.prototype._render = function (): VNode { |
1 | render: function (createElement) { |
再回到 _render 函数中的 render 方法的调用
1 | vnode = render.call(vm._renderProxy, vm.$createElement) |
render 函数中的 createElement 方法就是 vm.$createElement 方法:
1 | export function initRender (vm: Component) { |
vm._c 方法,它是被模板编译成的 render 函数使用。
vm.$createElement 是用户手写 render 方法使用的, 这俩个方法支持的参数相同,并且内部都调用了 createElement 方法。
Virtual DOM
用一个原生的 JS 对象去描述一个 DOM 节点,所以它比创建一个 DOM 的代价要小很多。在 Vue.js 中,Virtual DOM 是用 VNode 这么一个 Class 去描述,它是定义在 src/core/vdom/vnode.js 中的。
1 | export default class VNode { |
Vue.js 中 Virtual DOM 是借鉴了一个开源库 snabbdom 的实现,然后加入了一些 Vue.js 特色的东西:
https://github.com/snabbdom/snabbdom
VNode 是对真实 DOM 的一种抽象描述,它的核心定义无非就几个关键属性,标签名、数据、子节点、键值等,其它属性都是用来扩展 VNode 的灵活性以及实现一些特殊 feature 的。由于 VNode 只是用来映射到真实 DOM 的渲染,不需要包含操作 DOM 的方法,因此它是非常轻量和简单的。
createElement
Vue.js 利用 createElement 方法创建 VNode,它定义在 src/core/vdom/create-elemenet.js 中:
1 | // wrapper function for providing a more flexible interface |
createElement 方法实际上是对 _createElement 方法的封装,它允许传入的参数更加灵活,在处理这些参数后,调用真正创建 VNode 的函数 _createElement:
1 | export function _createElement ( |
createElement 函数的流程略微有点多,我们接下来主要分析 2 个重点的流程 —— children 的规范化以及 VNode 的创建。
- children 的规范化
由于 Virtual DOM 实际上是一个树状结构,每一个 VNode 可能会有若干个子节点,这些子节点应该也是 VNode 的类型。_createElement 接收的第 4 个参数 children 是任意类型的,因此我们需要把它们规范成 VNode 类型。
1 | // The template compiler attempts to minimize the need for normalization by |
simpleNormalizeChildren 方法调用场景是 render 函数是编译生成的。理论上编译生成的 children 都已经是 VNode 类型的,但这里有一个例外,就是 functional component 函数式组件返回的是一个数组而不是一个根节点,所以会通过 Array.prototype.concat 方法把整个 children 数组打平,让它的深度只有一层。
normalizeChildren 方法的调用场景有 2 种,一个场景是 render 函数是用户手写的,当 children 只有一个节点的时候,Vue.js 从接口层面允许用户把 children 写成基础类型用来创建单个简单的文本节点,这种情况会调用 createTextVNode 创建一个文本节点的 VNode;另一个场景是当编译 slot、v-for 的时候会产生嵌套数组的情况,会调用 normalizeArrayChildren 方法,接下来看一下它的实现:
1 | function normalizeArrayChildren (children: any, nestedIndex?: string): Array<VNode> { |
normalizeArrayChildren 接收 2 个参数,children 表示要规范的子节点,nestedIndex 表示嵌套的索引,因为单个 child 可能是一个数组类型。 normalizeArrayChildren 主要的逻辑就是遍历 children,获得单个节点 c,然后对 c 的类型判断,如果是一个数组类型,则递归调用 normalizeArrayChildren; 如果是基础类型,则通过 createTextVNode 方法转换成 VNode 类型;否则就已经是 VNode 类型了,如果 children 是一个列表并且列表还存在嵌套的情况,则根据 nestedIndex 去更新它的 key。这里需要注意一点,在遍历的过程中,对这 3 种情况都做了如下处理:如果存在两个连续的 text 节点,会把它们合并成一个 text 节点。
经过对 children 的规范化,children 变成了一个类型为 VNode 的 Array。
- VNode 的创建
1 | let vnode, ns |
这里先对 tag 做判断,如果是 string 类型,则接着判断如果是内置的一些节点,则直接创建一个普通 VNode,如果是为已注册的组件名,则通过 createComponent 创建一个组件类型的 VNode,否则创建一个未知的标签的 VNode。 如果是 tag 一个 Component 类型,则直接调用 createComponent 创建一个组件类型的 VNode 节点。
update
_update 方法的作用是把 VNode 渲染成真实的 DOM。
1 | Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) { |
_update 的核心就是调用 vm.__patch__ 方法:
1 | Vue.prototype.__patch__ = inBrowser ? patch : noop |
在浏览器端渲染中,它指向了 patch 方法,它的定义在 src/platforms/web/runtime/patch.js中:
1 | import * as nodeOps from 'web/runtime/node-ops' |
该方法的定义是调用 createPatchFunction 方法的返回值,这里传入了一个对象,包含 nodeOps 参数和 modules 参数。其中,nodeOps 封装了一系列 DOM 操作的方法,modules 定义了一些模块的钩子函数的实现,我们这里先不详细介绍,来看一下 createPatchFunction 的实现,它定义在 src/core/vdom/patch.js 中:
1 | const hooks = ['create', 'activate', 'update', 'remove', 'destroy'] |
createPatchFunction 内部定义了一系列的辅助方法,最终返回了一个 patch 方法,这个方法就赋值给了 vm._update 函数里调用的 vm.__patch__。
调用 createElm 方法,这个方法在这里非常重要,来看一下它的实现:
1 | function createElm ( |
createElm 的作用是通过虚拟节点创建真实的 DOM 并插入到它的父节点中。
判断 vnode 是否包含 tag,如果包含,先简单对 tag 的合法性在非生产环境下做校验,看是否是一个合法标签;然后再去调用平台 DOM 的操作去创建一个占位符元素。
1 | vnode.elm = vnode.ns |
接下来调用 createChildren 方法去创建子元素:
1 | createChildren(vnode, children, insertedVnodeQueue) |
createChildren 的逻辑很简单,实际上是遍历子虚拟节点,递归调用 createElm,这是一种常用的深度优先的遍历算法,这里要注意的一点是在遍历过程中会把 vnode.elm 作为父容器的 DOM 节点占位符传入。
接着再调用 invokeCreateHooks 方法执行所有的 create 的钩子并把 vnode push 到 insertedVnodeQueue 中。
1 | if (isDef(data)) { |
最后调用 insert 方法把 DOM 插入到父节点中,因为是递归调用,子元素会优先调用 insert,所以整个 vnode 树节点的插入顺序是先子后父。来看一下 insert 方法,它的定义在 src/core/vdom/patch.js 上。
1 | insert(parentElm, vnode.elm, refElm) |
1 | export function insertBefore (parentNode: Node, newNode: Node, referenceNode: Node) { |
再回到 patch 方法,首次渲染我们调用了 createElm 方法,这里传入的 parentElm 是 oldVnode.elm 的父元素,在我们的例子是 id 为 #app div 的父元素,也就是 Body;实际上整个过程就是递归创建了一个完整的 DOM 树并插入到 Body 上。
三、组件化
createComponent
1 | export function createComponent ( |
组件渲染这个 case 主要就 3 个关键步骤:构造子类构造函数,安装组件钩子函数和实例化 vnode。
- 构造子类构造函数
1 | const baseCtor = context.$options._base |
在这里 baseCtor 实际上就是 Vue
1 | // this is used to identify the "base" constructor to extend all plain-object |
Vue.extend 函数的定义,在 src/core/global-api/extend.js 中:
1 | /** |
Vue.extend 的作用就是构造一个 Vue 的子类,它使用一种非常经典的原型继承的方式把一个纯对象转换一个继承于 Vue 的构造器 Sub 并返回,然后对 Sub 这个对象本身扩展了一些属性,如扩展 options、添加全局 API 等;并且对配置中的 props 和 computed 做了初始化工作;最后对于这个 Sub 构造函数做了缓存,避免多次执行 Vue.extend 的时候对同一个子组件重复构造。
这样当我们去实例化 Sub 的时候,就会执行 this._init 逻辑再次走到了 Vue 实例的初始化逻辑:
1 | const Sub = function VueComponent (options) { |
- 安装组件钩子函数
1 | // install component management hooks onto the placeholder node |
在初始化一个 Component 类型的 VNode 的过程中实现了几个钩子函数:
1 | const componentVNodeHooks = { |
整个 installComponentHooks 的过程就是把 componentVNodeHooks 的钩子函数合并到 data.hook 中,在 VNode 执行 patch 的过程中执行相关的钩子函数。
- 实例化 VNode
1 | const name = Ctor.options.name || tag |
需要注意的是和普通元素节点的 vnode 不同,组件的 vnode 是没有 children 的,这点很关键!
patch
通过 createComponent 创建了组件 VNode,接下来会走到 vm._update,执行 vm.patch 去把 VNode 转换成真正的 DOM 节点。
patch 的过程会调用 createElm 创建元素节点,回顾一下 createElm 的实现,它的定义在 src/core/vdom/patch.js 中:
1 | function createElm ( |
createComponent 方法的实现:
1 | function createComponent (vnode, insertedVnodeQueue, parentElm, refElm) { |
如果 vnode 是一个组件 VNode,那么条件会满足,并且得到 i 就是 init 钩子函数
1 | init (vnode: VNodeWithData, hydrating: boolean): ?boolean { |
通过 createComponentInstanceForVnode 创建一个 Vue 的实例,然后调用 $mount 方法挂载子组件
1 | export function createComponentInstanceForVnode ( |
这里的 vnode.componentOptions.Ctor 对应的就是子组件的构造函数,我们上一节分析了它实际上是继承于 Vue 的一个构造器 Sub,相当于 new Sub(options) 这里有几个关键参数要注意几个点,_isComponent 为 true 表示它是一个组件,parent 表示当前激活的组件实例
1 | Vue.prototype._init = function (options?: Object) { |
1 | export function initInternalComponent (vm: Component, options: InternalComponentOptions) { |
这个过程我们重点记住以下几个点即可:opts.parent = options.parent、opts._parentVnode = parentVnode,它们是把之前我们通过 createComponentInstanceForVnode 函数传入的几个参数合并到内部的选项 $options 里了。
$mount 相当于执行 child.$mount(undefined, false),它最终会调用 mountComponent 方法,进而执行 vm._render() 方法:
1 | Vue.prototype._render = function (): VNode { |
执行完 vm._render 生成 VNode 后,接下来就要执行 vm._update 去渲染 VNode
1 | export let activeInstance: any = null |
对子组件的实例化过程先会调用 initInternalComponent(vm, options) 合并 options,把 parent 存储在 vm.$options 中,在 $mount 之前会调用 initLifecycle(vm) 方法:
1 | export function initLifecycle (vm: Component) { |
在完成组件的整个 patch 过程后,最后执行 insert(parentElm, vnode.elm, refElm) 完成组件的 DOM 插入,如果组件 patch 过程中又创建了子组件,那么DOM 的插入顺序是先子后父。
合并配置
new Vue 的过程通常有 2 种场景,一种是外部我们的代码主动调用 new Vue(options) 的方式实例化一个 Vue 对象;另一种是我们上一节分析的组件过程中内部通过 new Vue(options) 实例化子组件。无论哪种场景,都会执行实例的 _init(options) 方法,它首先会执行一个 merge options 的逻辑:
1 | Vue.prototype._init = function (options?: Object) { |
- 外部调用场景
当执行 new Vue 的时候,在执行 this._init(options) 的时候,就会执行如下逻辑去合并 options:
1 | vm.$options = mergeOptions( |
resolveConstructorOptions -> vm.constructor.options -> Vue.options
1 | export function initGlobalAPI (Vue: GlobalAPI) { |
mergeOptions
1 | /** |
mergeOptions 主要功能就是把 parent 和 child 这两个对象根据一些合并策略,合并成一个新对象并返回。比较核心的几步,先递归把 extends 和 mixins 合并到 parent 上,然后遍历 parent,调用 mergeField,然后再遍历 child,如果 key 不在 parent 的自身属性上,则调用 mergeField。
- 组件场景
组件的构造函数是通过 Vue.extend 继承自 Vue 的
1 | /** |
extendOptions 对应的就是前面定义的组件对象,它会和 Vue.options 合并到 Sub.opitons 中。
子组件的初始化过程
1 | export function createComponentInstanceForVnode ( |
options._isComponent 为 true,那么合并 options 的过程走到了 initInternalComponent(vm, options) 逻辑
1 | export function initInternalComponent (vm: Component, options: InternalComponentOptions) { |
子组件初始化过程通过 initInternalComponent 方式要比外部初始化 Vue 通过 mergeOptions 的过程要快,合并完的结果保留在 vm.$options 中
生命周期
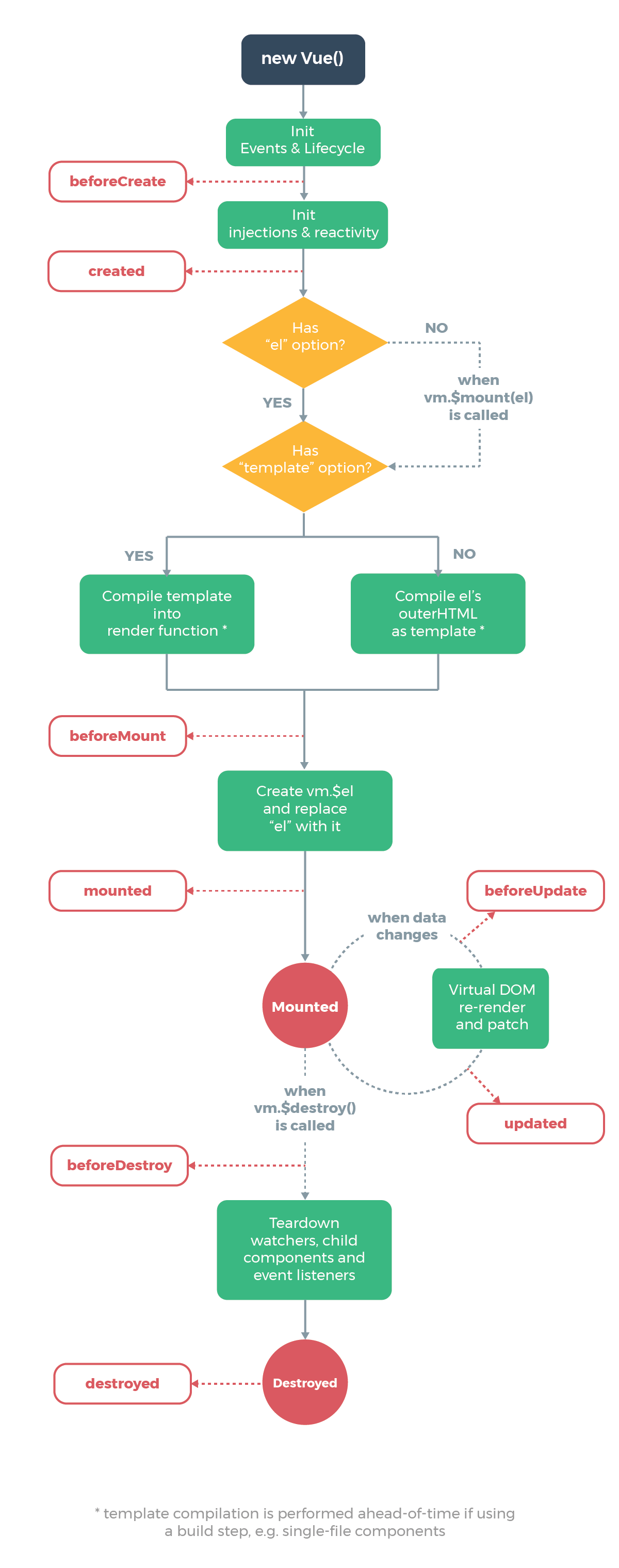
源码中最终执行生命周期的函数都是调用 callHook 方法
1 | export function callHook (vm: Component, hook: string) { |
callHook 函数的逻辑很简单,根据传入的字符串 hook,去拿到 vm.$options[hook] 对应的回调函数数组,然后遍历执行,执行的时候把 vm 作为函数执行的上下文。因此 callhook 函数的功能就是调用某个生命周期钩子注册的所有回调函数。
- beforeCreate & created
beforeCreate 和 created 函数都是在实例化 Vue 的阶段,在 _init 方法中执行
1 | Vue.prototype._init = function (options?: Object) { |
initState 的作用是初始化 props、data、methods、watch、computed 等属性。
- beforeMount & mounted
1 | export function mountComponent ( |
在执行 vm._render() 函数渲染 VNode 之前,执行了 beforeMount 钩子函数,在执行完 vm._update() 把 VNode patch 到真实 DOM 后,执行 mounted 钩子。
组件的 mounted 时机:
组件的 VNode patch 到 DOM 后,会执行 invokeInsertHook 函数,把 insertedVnodeQueue 里保存的钩子函数依次执行一遍
1 | function invokeInsertHook (vnode, queue, initial) { |
insert 钩子函数的定义:
1 | const componentVNodeHooks = { |
insertedVnodeQueue 的添加顺序是先子后父,所以对于同步渲染的子组件而言,mounted 钩子函数的执行顺序也是先子后父。
- beforeUpdate & updated
1 | export function mountComponent ( |
组件已经 mounted 之后,才会去调用这个钩子函数。
update 的执行时机是在 flushSchedulerQueue 函数调用的时候:
1 | function flushSchedulerQueue () { |
1 | export default class Watcher { |
把当前 wathcer 实例 push 到 vm._watchers 中,vm._watcher 是专门用来监听 vm 上数据变化然后重新渲染的,所以它是一个渲染相关的 watcher,因此在 callUpdatedHooks 函数中,只有 vm._watcher 的回调执行完毕后,才会执行 updated 钩子函数。
- beforeDestroy & destroyed
会调用 $destroy 方法
1 | Vue.prototype.$destroy = function () { |
beforeDestroy 钩子函数的执行时机是在 $destroy 函数执行最开始的地方,接着执行了一系列的销毁动作,包括从 parent 的 $children 中删掉自身,删除 watcher,当前渲染的 VNode 执行销毁钩子函数等,执行完毕后再调用 destroy 钩子函数。
在 $destroy 的执行过程中,它又会执行 vm.patch(vm._vnode, null) 触发它子组件的销毁钩子函数,这样一层层的递归调用,所以 destroy 钩子函数执行顺序是先子后父,和 mounted 过程一样。
- activated & deactivated
activated 和 deactivated 钩子函数是专门为 keep-alive 组件定制的钩子
组件注册
- 全局注册
1 | Vue.component('my-component', { |
Vue.component 函数定义过程发生在最开始初始化 Vue 的全局函数的时候
1 | import { ASSET_TYPES } from 'shared/constants' |
1 | export const ASSET_TYPES = [ |
所以实际上 Vue 是初始化了 3 个全局函数,并且如果 type 是 component 且 definition 是一个对象的话,通过 this.opitons._base.extend, 相当于 Vue.extend 把这个对象转换成一个继承于 Vue 的构造函数,最后通过 this.options[type + ‘s’][id] = definition 把它挂载到 Vue.options.components 上。
创建 vnode 的过程中,会执行 _createElement 方法
1 | export function _createElement ( |
1 | /** |
使用 Vue.component(id, definition) 全局注册组件的时候,id 可以是连字符、驼峰或首字母大写的形式。
- 局部注册
1 | import HelloWorld from './components/HelloWorld' |
组件的 Vue 的实例化阶段有一个合并 option 的逻辑,之前我们也分析过,所以就把 components 合并到 vm.$options.components 上,这样我们就可以在 resolveAsset 的时候拿到这个组件的构造函数,并作为 createComponent 的钩子的参数。
注意,局部注册和全局注册不同的是,只有该类型的组件才可以访问局部注册的子组件,而全局注册是扩展到 Vue.options 下,所以在所有组件创建的过程中,都会从全局的 Vue.options.components 扩展到当前组件的 vm.$options.components 下,这就是全局注册的组件能被任意使用的原因。
当我们使用到组件库的时候,往往更通用基础组件都是全局注册的,而编写的特例场景的业务组件都是局部注册的。
异步组件
1 | Vue.component('async-example', function (resolve, reject) { |
1 | export function createComponent ( |
1 | export function resolveAsyncComponent ( |
resolveAsyncComponent处理了 3 种异步组件的创建方式:
- 1 普通函数
1 | Vue.component('async-example', function (resolve, reject) { |
- 2 Promise
1 | Vue.component( |
- 3 高级
1 | const AsyncComp = () => ({ |
根据这 3 种异步组件的情况,来分别去分析 resolveAsyncComponent 的逻辑:
- 普通函数异步组件
实际加载逻辑,定义了 forceRender、resolve 和 reject 函数,注意 resolve 和 reject 函数用 once 函数做了一层包装
1 | /** |
const res = factory(resolve, reject)组件的工厂函数通常会先发送请求去加载我们的异步组件的 JS 文件,拿到组件定义的对象 res 后,执行 resolve(res) 逻辑,它会先执行 factory.resolved = ensureCtor(res, baseCtor):
1 | function ensureCtor (comp: any, base) { |
这个函数目的是为了保证能找到异步组件 JS 定义的组件对象,并且如果它是一个普通对象,则调用 Vue.extend 把它转换成一个组件的构造函数。
遍历 factory.contexts,拿到每一个调用异步组件的实例 vm, 执行 vm.$forceUpdate() 方法
1 | Vue.prototype.$forceUpdate = function () { |
Vue 通常是数据驱动视图重新渲染,但是在整个异步组件加载过程中是没有数据发生变化的,所以通过执行 $forceUpdate 可以强制组件重新渲染一次
- Promise 异步组件
webpack 2+ 支持了异步加载的语法糖:() => import(‘./my-async-component’),当执行完 res = factory(resolve, reject),返回的值就是 import(‘./my-async-component’) 的返回值,它是一个 Promise 对象。接着进入 if 条件,又判断了 typeof res.then === ‘function’),条件满足,执行:
1 | if (isUndef(factory.resolved)) { |
当组件异步加载成功后,执行 resolve,加载失败则执行 reject,这样就非常巧妙地实现了配合 webpack 2+ 的异步加载组件的方式(Promise)加载异步组件。
- 高级异步组件
高级异步组件的初始化逻辑和普通异步组件一样,也是执行 resolveAsyncComponent,当执行完 res = factory(resolve, reject),返回值就是定义的组件对象,显然满足 else if (isDef(res.component) && typeof res.component.then === ‘function’) 的逻辑,接着执行 res.component.then(resolve, reject),当异步组件加载成功后,执行 resolve,失败执行 reject。
先判断 res.error 是否定义了 error 组件,如果有的话则赋值给 factory.errorComp。 接着判断 res.loading 是否定义了 loading 组件,如果有的话则赋值给 factory.loadingComp,如果设置了 res.delay 且为 0,则设置 factory.loading = true,否则延时 delay 的时间执行:
1 | if (isUndef(factory.resolved) && isUndef(factory.error)) { |
最后判断 res.timeout,如果配置了该项,则在 res.timout 时间后,如果组件没有成功加载,执行 reject。
如果 delay 配置为 0,则这次直接渲染 loading 组件,否则则延时 delay 执行 forceRender,那么又会再一次执行到 resolveAsyncComponent。
异步组件加载失败
当异步组件加载失败,会执行 reject 函数:
1 | const reject = once(reason => { |
这个时候会把 factory.error 设置为 true,同时执行 forceRender() 再次执行到 resolveAsyncComponent:
1 | if (isTrue(factory.error) && isDef(factory.errorComp)) { |
那么这个时候就返回 factory.errorComp,直接渲染 error 组件。
异步组件加载成功
当异步组件加载成功,会执行 resolve 函数:
1 | const resolve = once((res: Object | Class<Component>) => { |
首先把加载结果缓存到 factory.resolved 中,这个时候因为 sync 已经为 false,则执行 forceRender() 再次执行到 resolveAsyncComponent:
1 | if (isDef(factory.resolved)) { |
那么这个时候直接返回 factory.resolved,渲染成功加载的组件。
异步组件加载中
如果异步组件加载中并未返回,这时候会走到这个逻辑:
1 | if (isTrue(factory.loading) && isDef(factory.loadingComp)) { |
那么则会返回 factory.loadingComp,渲染 loading 组件。
异步组件加载超时
如果超时,则走到了 reject 逻辑,之后逻辑和加载失败一样,渲染 error 组件
高级异步组件的实现是非常巧妙的,它实现了 loading、resolve、reject、timeout 4 种状态。异步组件实现的本质是 2 次渲染,除了 0 delay 的高级异步组件第一次直接渲染成 loading 组件外,其它都是第一次渲染生成一个注释节点,当异步获取组件成功后,再通过 forceRender 强制重新渲染,这样就能正确渲染出我们异步加载的组件了。
四、响应式原理
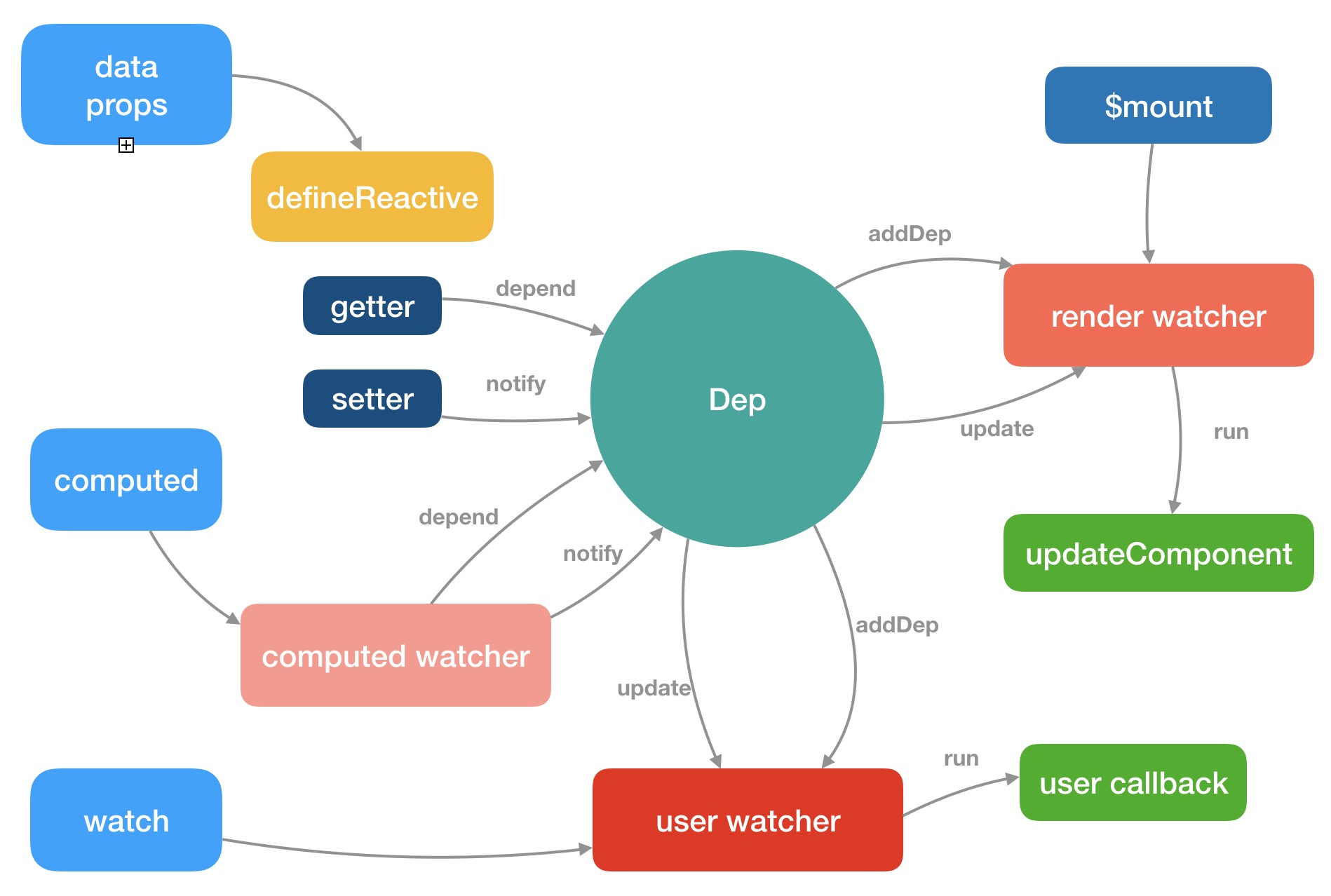
响应式对象
- Object.defineProperty
1 | Object.defineProperty(obj, prop, descriptor) |
obj 是要在其上定义属性的对象;prop 是要定义或修改的属性的名称;descriptor 是将被定义或修改的属性描述符。
对象拥有了 getter 和 setter,我们可以简单地把这个对象称为响应式对象。
- initState
1 | export function initState (vm: Component) { |
initState 方法主要是对 props、methods、data、computed 和 wathcer 等属性做了初始化操作。这里我们重点分析 props 和 data
initProps
1 | function initProps (vm: Component, propsOptions: Object) { |
props 的初始化主要过程,就是遍历定义的 props 配置。遍历的过程主要做两件事情:一个是调用 defineReactive 方法把每个 prop 对应的值变成响应式,可以通过 vm._props.xxx 访问到定义 props 中对应的属性。对于 defineReactive 方法,我们稍后会介绍;另一个是通过 proxy 把 vm._props.xxx 的访问代理到 vm.xxx 上,我们稍后也会介绍。
initData
1 | function initData (vm: Component) { |
data 的初始化主要过程也是做两件事,一个是对定义 data 函数返回对象的遍历,通过 proxy 把每一个值 vm._data.xxx 都代理到 vm.xxx 上;另一个是调用 observe 方法观测整个 data 的变化,把 data 也变成响应式,可以通过 vm._data.xxx 访问到定义 data 返回函数中对应的属性,observe 我们稍后会介绍。
- proxy
代理的作用是把 props 和 data 上的属性代理到 vm 实例上
1 | const sharedPropertyDefinition = { |
proxy 方法的实现很简单,通过 Object.defineProperty 把 target[sourceKey][key] 的读写变成了对 target[key] 的读写。所以对于 props 而言,对 vm._props.xxx 的读写变成了 vm.xxx 的读写,而对于 vm._props.xxx 我们可以访问到定义在 props 中的属性,所以我们就可以通过 vm.xxx 访问到定义在 props 中的 xxx 属性了。同理,对于 data 而言,对 vm._data.xxxx 的读写变成了对 vm.xxxx 的读写,而对于 vm._data.xxxx 我们可以访问到定义在 data 函数返回对象中的属性,所以我们就可以通过 vm.xxxx 访问到定义在 data 函数返回对象中的 xxxx 属性了。
- observe
1 | /** |
observe 方法的作用就是给非 VNode 的对象类型数据添加一个 Observer,如果已经添加过则直接返回,否则在满足一定条件下去实例化一个 Observer 对象实例。
- Observer
Observer 是一个类,它的作用是给对象的属性添加 getter 和 setter,用于依赖收集和派发更新:
1 | /** |
Observer 的构造函数逻辑很简单,首先实例化 Dep 对象,这块稍后会介绍,接着通过执行 def 函数把自身实例添加到数据对象 value 的 ob 属性上
1 | /** |
- defineReactive
defineReactive 的功能就是定义一个响应式对象,给对象动态添加 getter 和 setter
1 | /** |
defineReactive 函数最开始初始化 Dep 对象的实例,接着拿到 obj 的属性描述符,然后对子对象递归调用 observe 方法,这样就保证了无论 obj 的结构多复杂,它的所有子属性也能变成响应式的对象,这样我们访问或修改 obj 中一个嵌套较深的属性,也能触发 getter 和 setter。最后利用 Object.defineProperty 去给 obj 的属性 key 添加 getter 和 setter。目的就是为了在我们访问数据以及写数据的时候能自动执行一些逻辑:getter 做的事情是依赖收集,setter 做的事情是派发更新。
依赖收集
1 | export function defineReactive ( |
- Dep
Dep 是整个 getter 依赖收集的核心
1 | import type Watcher from './watcher' |
Dep 是一个 Class,它定义了一些属性和方法,这里需要特别注意的是它有一个静态属性 target,这是一个全局唯一 Watcher,这是一个非常巧妙的设计,因为在同一时间只能有一个全局的 Watcher 被计算,另外它的自身属性 subs 也是 Watcher 的数组。
- Watcher
1 | let uid = 0 |
Watcher 是一个 Class,在它的构造函数中,定义了一些和 Dep 相关的属性:
1 | this.deps = [] |
其中,this.deps 和 this.newDeps 表示 Watcher 实例持有的 Dep 实例的数组;而 this.depIds 和 this.newDepIds 分别代表 this.deps 和 this.newDeps 的 id Set
- 依赖收集过程分析
Vue 的 mount 过程是通过 mountComponent 函数
1 | updateComponent = () => { |
当我们去实例化一个渲染 watcher 的时候,首先进入 watcher 的构造函数逻辑,然后会执行它的 this.get() 方法,进入 get 函数,首先会执行:
1 | pushTarget(this) |
1 | export function pushTarget (_target: Watcher) { |
实际上就是把 Dep.target 赋值为当前的渲染 watcher 并压栈(为了恢复用)。
1 | value = this.getter.call(vm, vm) |
this.getter 对应就是 updateComponent 函数,这实际上就是在执行:
1 | vm._update(vm._render(), hydrating) |
vm._render() 方法,因为之前分析过这个方法会生成 渲染 VNode,并且在这个过程中会对 vm 上的数据访问,这个时候就触发了数据对象的 getter。
那么每个对象值的 getter 都持有一个 dep,在触发 getter 的时候会调用 dep.depend() 方法,也就会执行 Dep.target.addDep(this)。
1 | addDep (dep: Dep) { |
这时候会做一些逻辑判断(保证同一数据不会被添加多次)后执行 dep.addSub(this),那么就会执行 this.subs.push(sub),也就是说把当前的 watcher 订阅到这个数据持有的 dep 的 subs 中,这个目的是为后续数据变化时候能通知到哪些 subs 做准备。
1 | if (this.deep) { |
这个是要递归去访问 value,触发它所有子项的 getter
1 | popTarget() |
1 | Dep.target = targetStack.pop() |
实际上就是把 Dep.target 恢复成上一个状态,因为当前 vm 的数据依赖收集已经完成,那么对应的渲染Dep.target 也需要改变。最后执行:
1 | this.cleanupDeps() |
1 | cleanupDeps () { |
考虑到 Vue 是数据驱动的,所以每次数据变化都会重新 render,那么 vm._render() 方法又会再次执行,并再次触发数据的 getters,所以 Wathcer 在构造函数中会初始化 2 个 Dep 实例数组,newDeps 表示新添加的 Dep 实例数组,而 deps 表示上一次添加的 Dep 实例数组。
在执行 cleanupDeps 函数的时候,会首先遍历 deps,移除对 dep.subs 数组中 Wathcer 的订阅,然后把 newDepIds 和 depIds 交换,newDeps 和 deps 交换,并把 newDepIds 和 newDeps 清空。
派发更新
1 | /** |
遍历所有的 subs,也就是 Watcher 的实例数组,然后调用每一个 watcher 的 update 方法
1 | class Watcher { |
1 | const queue: Array<Watcher> = [] |
Vue 在做派发更新的时候的一个优化的点,它并不会每次数据改变都触发 watcher 的回调,而是把这些 watcher 先添加到一个队列里,然后在 nextTick 后执行 flushSchedulerQueue。
1 | let flushing = false |
- 队列排序
queue.sort((a, b) => a.id - b.id) 对队列做了从小到大的排序,这么做主要有以下要确保以下几点:
1.组件的更新由父到子;因为父组件的创建过程是先于子的,所以 watcher 的创建也是先父后子,执行顺序也应该保持先父后子。
2.用户的自定义 watcher 要优先于渲染 watcher 执行;因为用户自定义 watcher 是在渲染 watcher 之前创建的。
3.如果一个组件在父组件的 watcher 执行期间被销毁,那么它对应的 watcher 执行都可以被跳过,所以父组件的 watcher 应该先执行。
- 队列遍历
在对 queue 排序后,接着就是要对它做遍历,拿到对应的 watcher,执行 watcher.run()。这里需要注意一个细节,在遍历的时候每次都会对 queue.length 求值,因为在 watcher.run() 的时候,很可能用户会再次添加新的 watcher,这样会再次执行到 queueWatcher,如下:
1 | export function queueWatcher (watcher: Watcher) { |
- 状态恢复
1 | const queue: Array<Watcher> = [] |
把这些控制流程状态的一些变量恢复到初始值,把 watcher 队列清空。
watcher.run()
1 | class Watcher { |
run 函数实际上就是执行 this.getAndInvoke 方法,并传入 watcher 的回调函数。getAndInvoke 函数逻辑也很简单,先通过 this.get() 得到它当前的值,然后做判断,如果满足新旧值不等、新值是对象类型、deep 模式任何一个条件,则执行 watcher 的回调,注意回调函数执行的时候会把第一个和第二个参数传入新值 value 和旧值 oldValue,这就是当我们添加自定义 watcher 的时候能在回调函数的参数中拿到新旧值的原因。
对于渲染 watcher 而言,它在执行 this.get() 方法求值的时候,会执行 getter 方法:
1 | updateComponent = () => { |
实际上就是当数据发生变化的时候,触发 setter 逻辑,把在依赖过程中订阅的的所有观察者,也就是 watcher,都触发它们的 update 过程,这个过程又利用了队列做了进一步优化,在 nextTick 后执行所有 watcher 的 run,最后执行它们的回调函数。
nextTick
- JS 运行机制
JS 执行是单线程的,它是基于事件循环的。事件循环大致分为以下几个步骤:
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个”任务队列”(task queue)。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件。
(3)一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”,看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是 macro task 和 micro task,并且每个 macro task 结束后,都要清空所有的 micro task。
一段代码演示他们的执行顺序:
1 | for (macroTask of macroTaskQueue) { |
在浏览器环境中,常见的 macro task 有 setTimeout、MessageChannel、postMessage、setImmediate;常见的 micro task 有 MutationObsever 和 Promise.then。
- Vue 的实现
1 | import { noop } from 'shared/util' |
申明了 microTimerFunc 和 macroTimerFunc 2 个变量,它们分别对应的是 micro task 的函数和 macro task 的函数。对于 macro task 的实现,优先检测是否支持原生 setImmediate,这是一个高版本 IE 和 Edge 才支持的特性,不支持的话再去检测是否支持原生的 MessageChannel,如果也不支持的话就会降级为 setTimeout 0;而对于 micro task 的实现,则检测浏览器是否原生支持 Promise,不支持的话直接指向 macro task 的实现。
这里使用 callbacks 而不是直接在 nextTick 中执行回调函数的原因是保证在同一个 tick 内多次执行 nextTick,不会开启多个异步任务,而把这些异步任务都压成一个同步任务,在下一个 tick 执行完毕。
当 nextTick 不传 cb 参数的时候,提供一个 Promise 化的调用,比如:
1 | nextTick().then(() => {}) |
withMacroTask 函数,它是对函数做一层包装,确保函数执行过程中对数据任意的修改,触发变化执行 nextTick 的时候强制走 macroTimerFunc。比如对于一些 DOM 交互事件,如 v-on 绑定的事件回调函数的处理,会强制走 macro task。
Vue.js 提供了 2 种调用 nextTick 的方式,一种是全局 API Vue.nextTick,一种是实例上的方法 vm.$nextTick,无论我们使用哪一种,最后都是调用 next-tick.js 中实现的 nextTick 方法。
检测变化的注意事项
- 对象添加属性
1 | Vue.set = set |
1 | /** |
set 方法接收 3个参数,target 可能是数组或者是普通对象,key 代表的是数组的下标或者是对象的键值,val 代表添加的值。首先判断如果 target 是数组且 key 是一个合法的下标,则之前通过 splice 去添加进数组然后返回,这里的 splice 其实已经不仅仅是原生数组的 splice 了,稍后我会详细介绍数组的逻辑。接着又判断 key 已经存在于 target 中,则直接赋值返回,因为这样的变化是可以观测到了。接着再获取到 target.ob 并赋值给 ob,之前分析过它是在 Observer 的构造函数执行的时候初始化的,表示 Observer 的一个实例,如果它不存在,则说明 target 不是一个响应式的对象,则直接赋值并返回。最后通过 defineReactive(ob.value, key, val) 把新添加的属性变成响应式对象,然后再通过 ob.dep.notify() 手动的触发依赖通知,还记得我们在给对象添加 getter 的时候有这么一段逻辑:
1 | export function defineReactive ( |
在 getter 过程中判断了 childOb,并调用了 childOb.dep.depend() 收集了依赖,这就是为什么执行 Vue.set 的时候通过 ob.dep.notify() 能够通知到 watcher,从而让添加新的属性到对象也可以检测到变化。这里如果 value 是个数组,那么就通过 dependArray 把数组每个元素也去做依赖收集。
- 数组
接着说一下数组的情况,Vue 也是不能检测到以下变动的数组:
1.当你利用索引直接设置一个项时,例如:vm.items[indexOfItem] = newValue
2.当你修改数组的长度时,例如:vm.items.length = newLength
对于第一种情况,可以使用:Vue.set(example1.items, indexOfItem, newValue);而对于第二种情况,可以使用 vm.items.splice(newLength)。
通过 observe 方法去观察对象的时候会实例化 Observer:
1 | export class Observer { |
1 | /** |
protoAugment 方法是直接把 target.proto 原型直接修改为 src,而 copyAugment 方法是遍历 keys,通过 def,也就是 Object.defineProperty 去定义它自身的属性值。对于大部分现代浏览器都会走到 protoAugment,那么它实际上就把 value 的原型指向了 arrayMethods
1 | import { def } from '../util/index' |
可以看到,arrayMethods 首先继承了 Array,然后对数组中所有能改变数组自身的方法,如 push、pop 等这些方法进行重写。重写后的方法会先执行它们本身原有的逻辑,并对能增加数组长度的 3 个方法 push、unshift、splice 方法做了判断,获取到插入的值,然后把新添加的值变成一个响应式对象,并且再调用 ob.dep.notify() 手动触发依赖通知,这就很好地解释了之前的示例中调用 vm.items.splice(newLength) 方法可以检测到变化。
计算属性 VS 侦听属性
- computed
1、初始化过程:
计算属性的初始化是发生在 Vue 实例初始化阶段的 initState 函数中,执行了 if (opts.computed) initComputed(vm, opts.computed)
1 | const computedWatcherOptions = { computed: true } |
函数首先创建 vm._computedWatchers 为一个空对象,接着对 computed 对象做遍历,拿到计算属性的每一个 userDef,然后尝试获取这个 userDef 对应的 getter 函数,拿不到则在开发环境下报警告。接下来为每一个 getter 创建一个 watcher,这个 watcher 和渲染 watcher 有一点很大的不同,它是一个 computed watcher,因为 const computedWatcherOptions = { computed: true }。computed watcher 和普通 watcher 的差别我稍后会介绍。最后对判断如果 key 不是 vm 的属性,则调用 defineComputed(vm, key, userDef),否则判断计算属性对于的 key 是否已经被 data 或者 prop 所占用,如果是的话则在开发环境报相应的警告。
1 | export function defineComputed ( |
利用 Object.defineProperty 给计算属性对应的 key 值添加 getter 和 setter
1 | function createComputedGetter (key) { |
createComputedGetter 返回一个函数 computedGetter,它就是计算属性对应的 getter。
2、求值过程
1 | constructor ( |
可以发现 computed watcher 会并不会立刻求值,同时持有一个 dep 实例。然后当我们的 render 函数执行访问到 this.fullName 的时候,就触发了计算属性的 getter,它会拿到计算属性对应的 watcher,然后执行 watcher.depend()
1 | /** |
这时候的 Dep.target 是渲染 watcher,所以 this.dep.depend() 相当于渲染 watcher 订阅了这个 computed watcher 的变化。然后再执行 watcher.evaluate() 去求值
1 | /** |
在求值过程中,会执行 value = this.getter.call(vm, vm),这实际上就是执行了计算属性定义的 getter 函数
3、依赖的数据变化后的逻辑
对计算属性依赖的数据做修改,则会触发 setter 过程,通知所有订阅它变化的 watcher 更新,执行 watcher.update() 方法:
1 | /* istanbul ignore else */ |
1 | this.getAndInvoke(() => { |
getAndInvoke 函数会重新计算,然后对比新旧值,如果变化了则执行回调函数,那么这里这个回调函数是 this.dep.notify()
计算属性本质上就是一个 computed watcher!!
- watch
发生在 Vue 的实例初始化阶段的 initState 函数中,在 computed 初始化之后,执行了:
1 | if (opts.watch && opts.watch !== nativeWatch) { |
1 | function initWatch (vm: Component, watch: Object) { |
1 | function createWatcher ( |
1 | Vue.prototype.$watch = function ( |
侦听属性 watch 最终会调用 $watch 方法,这个方法首先判断 cb 如果是一个对象,则调用 createWatcher 方法,这是因为 $watch 方法是用户可以直接调用的,它可以传递一个对象,也可以传递函数。接着执行 const watcher = new Watcher(vm, expOrFn, cb, options) 实例化了一个 watcher,这里需要注意一点这是一个 user watcher,因为 options.user = true。通过实例化 watcher 的方式,一旦我们 watch 的数据发送变化,它最终会执行 watcher 的 run 方法,执行回调函数 cb,并且如果我们设置了 immediate 为 true,则直接会执行回调函数 cb。最后返回了一个 unwatchFn 方法,它会调用 teardown 方法去移除这个 watcher。
侦听属性也是基于 Watcher 实现的,它是一个 user watcher
Watcher options:
deep
user
computed
sync
计算属性适合用在模板渲染中,某个值是依赖了其它的响应式对象甚至是计算属性计算而来;而侦听属性适用于观测某个值的变化去完成一段复杂的业务逻辑。
组件更新
当数据发生变化的时候,会触发渲染 watcher 的回调函数,进而执行组件的更新过程
1 | updateComponent = () => { |
vm._update
1 | Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) { |
patch
1 | return function patch (oldVnode, vnode, hydrating, removeOnly) { |
这里执行 patch 的逻辑和首次渲染是不一样的,因为 oldVnode 不为空,并且它和 vnode 都是 VNode 类型,接下来会通过 sameVNode(oldVnode, vnode) 判断它们是否是相同的 VNode 来决定走不同的更新逻辑:
1 | function sameVnode (a, b) { |
sameVnode 的逻辑非常简单,如果两个 vnode 的 key 不相等,则是不同的;否则继续判断对于同步组件,则判断 isComment、data、input 类型等是否相同,对于异步组件,则判断 asyncFactory 是否相同。
- 新旧节点不同
替换已存在的节点,大致分为 3 步
1、创建新节点
1 | const oldElm = oldVnode.elm |
以当前旧节点为参考节点,创建新的节点,并插入到 DOM 中
2、更新父的占位符节点
1 | // update parent placeholder node element, recursively |
找到当前 vnode 的父的占位符节点,先执行各个 module 的 destroy 的钩子函数,如果当前占位符是一个可挂载的节点,则执行 module 的 create 钩子函数
3、删除旧节点
1 | // destroy old node |
把 oldVnode 从当前 DOM 树中删除,如果父节点存在,则执行 removeVnodes 方法:
1 | function removeVnodes (parentElm, vnodes, startIdx, endIdx) { |
删除节点逻辑很简单,就是遍历待删除的 vnodes 做删除,其中 removeAndInvokeRemoveHook 的作用是从 DOM 中移除节点并执行 module 的 remove 钩子函数,并对它的子节点递归调用 removeAndInvokeRemoveHook 函数;invokeDestroyHook 是执行 module 的 destory 钩子函数以及 vnode 的 destory 钩子函数,并对它的子 vnode 递归调用 invokeDestroyHook 函数;removeNode 就是调用平台的 DOM API 去把真正的 DOM 节点移除。
组件生命周期的时候提到 beforeDestroy & destroyed 这两个生命周期钩子函数,它们就是在执行 invokeDestroyHook 过程中,执行了 vnode 的 destory 钩子函数
1 | const componentVNodeHooks = { |
- 新旧节点相同
patchVNode
1 | function patchVnode (oldVnode, vnode, insertedVnodeQueue, removeOnly) { |
patchVnode 的作用就是把新的 vnode patch 到旧的 vnode 上
1、执行 prepatch 钩子函数
1 | let i |
当更新的 vnode 是一个组件 vnode 的时候,会执行 prepatch 的方法
1 | const componentVNodeHooks = { |
1 | export function updateChildComponent ( |
updateChildComponent 的逻辑也非常简单,由于更新了 vnode,那么 vnode 对应的实例 vm 的一系列属性也会发生变化,包括占位符 vm.$vnode 的更新、slot 的更新,listeners 的更新,props 的更新等等。
2、执行 update 钩子函数
1 | if (isDef(data) && isPatchable(vnode)) { |
回到 patchVNode 函数,在执行完新的 vnode 的 prepatch 钩子函数,会执行所有 module 的 update 钩子函数以及用户自定义 update 钩子函数
3、完成 patch 过程
1 | const oldCh = oldVnode.children |
4、执行 postpatch 钩子函数
1 | if (isDef(data)) { |
组件更新的过程核心就是新旧 vnode diff,对新旧节点相同以及不同的情况分别做不同的处理。新旧节点不同的更新流程是创建新节点->更新父占位符节点->删除旧节点;而新旧节点相同的更新流程是去获取它们的 children,根据不同情况做不同的更新逻辑。最复杂的情况是新旧节点相同且它们都存在子节点,那么会执行 updateChildren 逻辑。
Props
- 规范化
初始化 props 之前,首先会对 props 做一次 normalize,它发生在 mergeOptions 的时候
1 | export function mergeOptions ( |
normalizeProps 函数的主要目的就是把我们编写的 props 转成对象格式,因为实际上 props 除了对象格式,还允许写成数组格式。
- 初始化
Props 的初始化主要发生在 new Vue 中的 initState 阶段
1 | export function initState (vm: Component) { |
initProps 主要做 3 件事情:校验、响应式和代理。
- Props 更新
1、子组件 props 更新
在父组件重新渲染的最后,会执行 patch 过程,进而执行 patchVnode 函数,patchVnode 通常是一个递归过程,当它遇到组件 vnode 的时候,会执行组件更新过程的 prepatch 钩子函数
1 | function patchVnode ( |
1 | prepatch (oldVnode: MountedComponentVNode, vnode: MountedComponentVNode) { |
内部会调用 updateChildComponent 方法来更新 props,注意第二个参数就是父组件的 propData,那么为什么 vnode.componentOptions.propsData 就是父组件传递给子组件的 prop 数据呢(这个也同样解释了第一次渲染的 propsData 来源)?原来在组件的 render 过程中,对于组件节点会通过 createComponent 方法来创建组件 vnode:
1 | export function createComponent ( |
在创建组件 vnode 的过程中,首先从 data 中提取出 propData,然后在 new VNode 的时候,作为第七个参数 VNodeComponentOptions 中的一个属性传入,所以我们可以通过 vnode.componentOptions.propsData 拿到 prop 数据。
1 | export function updateChildComponent ( |
我们重点来看更新 props 的相关逻辑,这里的 propsData 是父组件传递的 props 数据,vm 是子组件的实例。vm._props 指向的就是子组件的 props 值,propKeys 就是在之前 initProps 过程中,缓存的子组件中定义的所有 prop 的 key。主要逻辑就是遍历 propKeys,然后执行 props[key] = validateProp(key, propOptions, propsData, vm) 重新验证和计算新的 prop 数据,更新 vm._props,也就是子组件的 props,这个就是子组件 props 的更新过程。
2、子组件重新渲染
先来看一下 prop 值被修改的情况,当执行 props[key] = validateProp(key, propOptions, propsData, vm) 更新子组件 prop 的时候,会触发 prop 的 setter 过程,只要在渲染子组件的时候访问过这个 prop 值,那么根据响应式原理,就会触发子组件的重新渲染。
再来看一下当对象类型的 prop 的内部属性发生变化的时候,这个时候其实并没有触发子组件 prop 的更新。但是在子组件的渲染过程中,访问过这个对象 prop,所以这个对象 prop 在触发 getter 的时候会把子组件的 render watcher 收集到依赖中,然后当我们在父组件更新这个对象 prop 的某个属性的时候,会触发 setter 过程,也就会通知子组件 render watcher 的 update,进而触发子组件的重新渲染。
五、编译
模板到真实 DOM 渲染的过程,中间有一个环节是把模板编译成 render 函数,这个过程我们把它称作编译。
Vue.js 提供了 2 个版本,一个是 Runtime + Compiler 的,一个是 Runtime only 的,前者是包含编译代码的,可以把编译过程放在运行时做,后者是不包含编译代码的,需要借助 webpack 的 vue-loader 事先把模板编译成 render函数。
- 编译入口
1 | const mount = Vue.prototype.$mount |
compileToFunctions 方法就是把模板 template 编译生成 render 以及 staticRenderFns
1 | import { baseOptions } from './options' |
1 | // `createCompilerCreator` allows creating compilers that use alternative |
createCompiler 方法实际上是通过调用 createCompilerCreator 方法返回的,该方法传入的参数是一个函数,真正的编译过程都在这个 baseCompile 函数里执行
1 | export function createCompilerCreator (baseCompile: Function): Function { |
1 | export function createCompileToFunctionFn (compile: Function): Function { |
核心的编译过程就一行代码:
1 | const compiled = compile(template, options) |
1 | function compile ( |
compile 函数执行的逻辑是先处理配置参数,真正执行编译过程就一行代码:
1 | const compiled = baseCompile(template, finalOptions) |
baseCompile 在执行 createCompilerCreator 方法时作为参数传入
1 | export const createCompiler = createCompilerCreator(function baseCompile ( |
编译的入口我们终于找到了,它主要就是执行了如下几个逻辑:
1、解析模板字符串生成 AST
1 | const ast = parse(template.trim(), options) |
流程:
a.从 options 中获取方法和配置
b.解析 HTML 模板
b-1.处理开始标签(创建 AST 元素,处理 AST 元素,AST 树管理)
b-2.处理闭合标签
b-3.处理文本内容
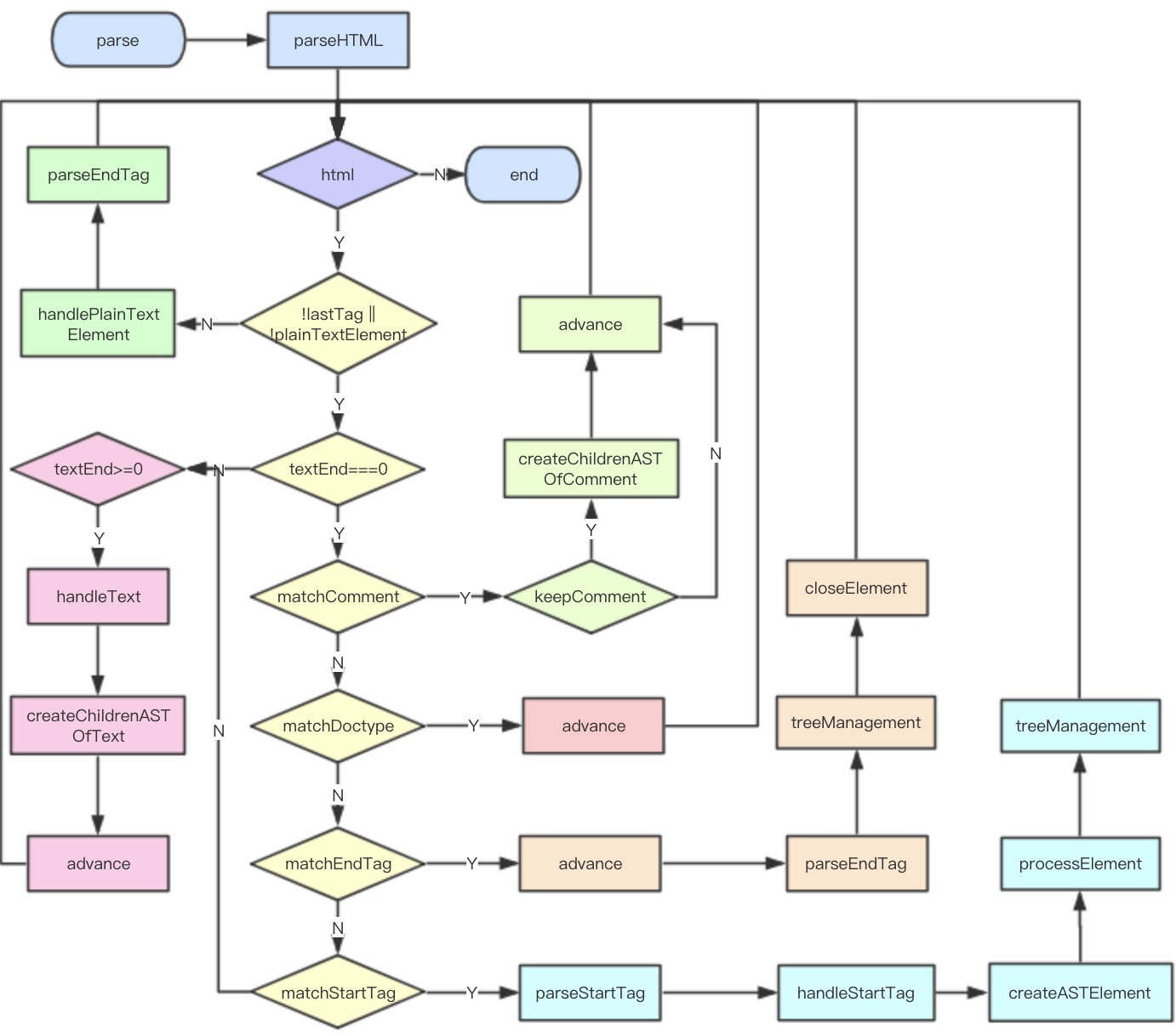
parse 的目标是把 template 模板字符串转换成 AST 树,它是一种用 JavaScript 对象的形式来描述整个模板。那么整个 parse 的过程是利用正则表达式顺序解析模板,当解析到开始标签、闭合标签、文本的时候都会分别执行对应的回调函数,来达到构造 AST 树的目的。
2、优化语法树
1 | optimize(ast, options) |
整个 optimize 的过程实际上就干 2 件事情,markStatic(root) 标记静态节点 ,markStaticRoots(root, false) 标记静态根。
经过 optimize 后每一个 AST 元素节点都多了 staic 属性,并且 type 为 1 的普通元素 AST 节点多了 staticRoot 属性。
3、生成代码
1 | const code = generate(ast, options) |
1 | export function generate ( |
generate 函数首先通过 genElement(ast, state) 生成 code,再把 code 用 with(this){return ${code}}} 包裹起来。
1 | export function genElement (el: ASTElement, state: CodegenState): string { |
ast -> code 编译后生成的代码就是在运行时执行的代码。
六、扩展
event
- 原生 DOM 事件
add 和 remove 的逻辑很简单,就是实际上调用原生 addEventListener 和 removeEventListener,并根据参数传递一些配置,注意这里的 hanlder 会用 withMacroTask(hanlder) 包裹一下
1 | export function withMacroTask (fn: Function): Function { |
实际上就是强制在 DOM 事件的回调函数执行期间如果修改了数据,那么这些数据更改推入的队列会被当做 macroTask 在 nextTick 后执行。
- 用户自定义事件
自定义事件和原生 DOM 事件处理的差异就在事件添加和删除的实现上,来看一下自定义事件 add 和 remove 的实现:
1 | function add (event, fn, once) { |
1 | export function eventsMixin (Vue: Class<Component>) { |
把所有的事件用 vm._events 存储起来,当执行 vm.$on(event,fn) 的时候,按事件的名称 event 把回调函数 fn 存储起来 vm._events[event].push(fn)。当执行 vm.$emit(event) 的时候,根据事件名 event 找到所有的回调函数 let cbs = vm._events[event],然后遍历执行所有的回调函数。当执行 vm.$off(event,fn) 的时候会移除指定事件名 event 和指定的 fn 当执行 vm.$once(event,fn) 的时候,内部就是执行 vm.$on,并且当回调函数执行一次后再通过 vm.$off 移除事件的回调,这样就确保了回调函数只执行一次。
Vue 支持 2 种事件类型,原生 DOM 事件和自定义事件,它们主要的区别在于添加和删除事件的方式不一样,并且自定义事件的派发是往当前实例上派发,但是可以利用在父组件环境定义回调函数来实现父子组件的通讯。另外要注意一点,只有组件节点才可以添加自定义事件,并且添加原生 DOM 事件需要使用 native 修饰符;而普通元素使用 .native 修饰符是没有作用的,也只能添加原生 DOM 事件。
v-model
v-model 即可以作用在普通表单元素上,又可以作用在组件上,它其实是一个语法糖
- 表单元素
1 | addProp(el, 'value', `(${value})`) |
这实际上就是 input 实现 v-model 的精髓,通过修改 AST 元素,给 el 添加一个 prop,相当于我们在 input 上动态绑定了 value,又给 el 添加了事件处理,相当于在 input 上绑定了 input 事件,其实转换成模板如下:
1 | <input |
其实就是动态绑定了 input 的 value 指向了 messgae 变量,并且在触发 input 事件的时候去动态把 message 设置为目标值,这样实际上就完成了数据双向绑定了,所以说 v-model 实际上就是语法糖。
- 组件
典型的 Vue 的父子组件通讯模式,父组件通过 prop 把数据传递到子组件,子组件修改了数据后把改变通过 $emit 事件的方式通知父组件,所以说组件上的 v-model 也是一种语法糖。
组件 v-model 的实现,子组件的 value prop 以及派发的 input 事件名是可配的,可以看到 transformModel 中对这部分的处理:
1 | function transformModel (options, data: any) { |
举个例子:
1 | let Child = { |
slot
插槽分为普通插槽和作用域插槽,它们可以解决不同的场景
普通插槽
作用域插槽
普通插槽和作用域插槽的实现。它们有一个很大的差别是数据作用域,普通插槽是在父组件编译和渲染阶段生成 vnodes,所以数据的作用域是父组件实例,子组件渲染的时候直接拿到这些渲染好的 vnodes。而对于作用域插槽,父组件在编译和渲染阶段并不会直接生成 vnodes,而是在父节点 vnode 的 data 中保留一个 scopedSlots 对象,存储着不同名称的插槽以及它们对应的渲染函数,只有在编译和渲染子组件阶段才会执行这个渲染函数生成 vnodes,由于是在子组件环境执行的,所以对应的数据作用域是子组件实例。两种插槽的目的都是让子组件 slot 占位符生成的内容由父组件来决定,但数据的作用域会根据它们 vnodes 渲染时机不同而不同。
keep-alive
- 内置组件
由于我们也是在
如果命中缓存,则直接从缓存中拿 vnode 的组件实例,并且重新调整了 key 的顺序放在了最后一个;否则把 vnode 设置进缓存,最后还有一个逻辑,如果配置了 max 并且缓存的长度超过了 this.max,还要从缓存中删除第一个:
除了从缓存中删除外,还要判断如果要删除的缓存并的组件 tag 不是当前渲染组件 tag,也执行删除缓存的组件实例的 $destroy 方法。最后设置 vnode.data.keepAlive = true
1 | watch: { |
观测他们的变化执行 pruneCache 函数,其实就是对 cache 做遍历,发现缓存的节点名称和新的规则没有匹配上的时候,就把这个缓存节点从缓存中摘除。
- 组件渲染
1.首次渲染
createComponent 定义了 isReactivated 的变量,它是根据 vnode.componentInstance 以及 vnode.data.keepAlive 的判断,第一次渲染的时候,vnode.componentInstance 为 undefined,vnode.data.keepAlive 为 true,因为它的父组件
1 | function initComponent (vnode, insertedVnodeQueue) { |
对于首次渲染而言,除了在
- 缓存渲染
patchVnode 在做各种 diff 之前,会先执行 prepatch 的钩子函数,prepatch 核心逻辑就是执行 updateChildComponent 方法
1 | export function updateChildComponent ( |
被
1 | function reactivateComponent (vnode, insertedVnodeQueue, parentElm, refElm) { |
生命周期
- activated
遍历所有的 activatedChildren,执行 activateChildComponent 方法,通过队列调的方式就是把整个 activated 时机延后了。
- deactivated
发生在 vnode 的 destory 钩子函数
1 | const componentVNodeHooks = { |
1 | export function deactivateChildComponent (vm: Component, direct?: boolean) { |
执行组件的 deacitvated 钩子函数,并且递归去执行它的所有子组件的 deactivated 钩子函数。
transition
- 内置组件
处理 children
处理 mode
获取 rawChild & child
处理 id & data
- transition module
过渡动画提供了 2 个时机,一个是 create 和 activate 的时候提供了 entering 进入动画,一个是 remove 的时候提供了 leaving 离开动画
entering
leaving
Vue 的过渡实现分为以下几个步骤:
1.自动嗅探目标元素是否应用了 CSS 过渡或动画,如果是,在恰当的时机添加/删除 CSS 类名。
2.如果过渡组件提供了 JavaScript 钩子函数,这些钩子函数将在恰当的时机被调用。
3.如果没有找到 JavaScript 钩子并且也没有检测到 CSS 过渡/动画,DOM 操作 (插入/删除) 在下一帧中立即执行。
所以真正执行动画的是我们写的 CSS 或者是 JavaScript 钩子函数,而 Vue 的
transition-group
实现了列表的过渡效果
render 函数
move 过渡实现
七、Vue-Router
路由注册
- Vue.use
Vue 提供了 Vue.use 的全局 API 来注册这些插件,Vue.use 接受一个 plugin 参数,并且维护了一个 _installedPlugins 数组,它存储所有注册过的 plugin;接着又会判断 plugin 有没有定义 install 方法,如果有的话则调用该方法,并且该方法执行的第一个参数是 Vue;最后把 plugin 存储到 installedPlugins 中。
- 路由安装
Vue-Router 安装最重要的一步就是利用 Vue.mixin 去把 beforeCreate 和 destroyed 钩子函数注入到每一个组件中。
VueRouter 对象
1 | export default class VueRouter { |
构造函数定义了一些属性,其中 this.app 表示根 Vue 实例,this.apps 保存持有 $options.router 属性的 Vue 实例,this.options 保存传入的路由配置,this.beforeHooks、 this.resolveHooks、this.afterHooks 表示一些钩子函数,我们之后会介绍,this.matcher 表示路由匹配器,我们之后会介绍,this.fallback 表示在浏览器不支持 history.pushState 的情况下,根据传入的 fallback 配置参数,决定是否回退到hash模式,this.mode 表示路由创建的模式,this.history 表示路由历史的具体的实现实例,它是根据 this.mode 的不同实现不同,它有 History 基类,然后不同的 history 实现都是继承 History。
组件在执行 beforeCreate 钩子函数的时候,如果传入了 router 实例,都会执行 router.init 方法:
init 的逻辑很简单,它传入的参数是 Vue 实例,然后存储到 this.apps 中;只有根 Vue 实例会保存到 this.app 中,并且会拿到当前的 this.history,根据它的不同类型来执行不同逻辑,由于我们平时使用 hash 路由多一些,所以我们先看这部分逻辑,先定义了 setupHashListener 函数,接着执行了 history.transitionTo 方法,它是定义在 History 基类中
1 | transitionTo (location: RawLocation, onComplete?: Function, onAbort?: Function) { |
1 | match ( |
matcher
- createMatcher
1 | export function createMatcher ( |
createMatcher 接收 2 个参数,一个是 router,它是我们 new VueRouter 返回的实例,一个是 routes,它是用户定义的路由配置
createMathcer 首先执行的逻辑是 const { pathList, pathMap, nameMap } = createRouteMap(routes) 创建一个路由映射表
1 | export function createRouteMap ( |
createRouteMap 函数的目标是把用户的路由配置转换成一张路由映射表,它包含 3 个部分,pathList 存储所有的 path,pathMap 表示一个 path 到 RouteRecord 的映射关系,而 nameMap 表示 name 到 RouteRecord 的映射关系。
1 | declare type RouteRecord = { |
由于 pathList、pathMap、nameMap 都是引用类型,所以在遍历整个 routes 过程中去执行 addRouteRecord 方法,会不断给他们添加数据。那么经过整个 createRouteMap 方法的执行,我们得到的就是 pathList、pathMap 和 nameMap。其中 pathList 是为了记录路由配置中的所有 path,而 pathMap 和 nameMap 都是为了通过 path 和 name 能快速查到对应的 RouteRecord。
matcher 是一个对象,它对外暴露了 match 和 addRoutes 方法。
- addRoutes
1 | function addRoutes (routes) { |
- match
1 | function match ( |
match 方法接收 3 个参数,其中 raw 是 RawLocation 类型,它可以是一个 url 字符串,也可以是一个 Location 对象;currentRoute 是 Route 类型,它表示当前的路径;redirectedFrom 和重定向相关,这里先忽略。match 方法返回的是一个路径,它的作用是根据传入的 raw 和当前的路径 currentRoute 计算出一个新的路径并返回。
1 | function _createRoute ( |
1 | export function createRoute ( |
在 Vue-Router 中,所有的 Route 最终都会通过 createRoute 函数创建,并且它最后是不可以被外部修改的。Route 对象中有一个非常重要属性是 matched,它通过 formatMatch(record) 计算而来:
1 | function formatMatch (record: ?RouteRecord): Array<RouteRecord> { |
路径切换
1 | transitionTo (location: RawLocation, onComplete?: Function, onAbort?: Function) { |
transitionTo 首先根据目标 location 和当前路径 this.current 执行 this.router.match 方法去匹配到目标的路径。这里 this.current 是 history 维护的当前路径
transitionTo 实际上也就是在切换 this.current
current.matched 和 route.matched 执行了 resolveQueue 方法解析出 3 个队列:
因为 route.matched 是一个 RouteRecord 的数组,由于路径是由 current 变向 route,那么就遍历对比 2 边的 RouteRecord,找到一个不一样的位置 i,那么 next 中从 0 到 i 的 RouteRecord 是两边都一样,则为 updated 的部分;从 i 到最后的 RouteRecord 是 next 独有的,为 activated 的部分;而 current 中从 i 到最后的 RouteRecord 则没有了,为 deactivated 的部分。
拿到 updated、activated、deactivated 3 个 ReouteRecord 数组后,接下来就是路径变换后的一个重要部分,执行一系列的钩子函数。
- 导航守卫
queue 是怎么构造的:
1 | const queue: Array<?NavigationGuard> = [].concat( |
按照顺序如下:
1.在失活的组件里调用离开守卫。
2.调用全局的 beforeEach 守卫。
3.在重用的组件里调用 beforeRouteUpdate 守卫
4.在激活的路由配置里调用 beforeEnter。
5.解析异步路由组件。
6.在被激活的组件里调用 beforeRouteEnter。
7.调用全局的 beforeResolve 守卫。
8.调用全局的 afterEach 钩子。
路由切换除了执行这些钩子函数,从表象上有 2 个地方会发生变化,一个是 url 发生变化,一个是组件发生变化。
- url
1 | push (location: RawLocation, onComplete?: Function, onAbort?: Function) { |
pushState 会调用浏览器原生的 history 的 pushState 接口或者 replaceState 接口,更新浏览器的 url 地址,并把当前 url 压入历史栈中。
- 组件
<router-view> 是一个 functional 组件,它的渲染也是依赖 render 函数,那么
1 | const route = parent.$route |
1 | Object.defineProperty(Vue.prototype, '$route', { |
路由始终会维护当前的线路,路由切换的时候会把当前线路切换到目标线路,切换过程中会执行一系列的导航守卫钩子函数,会更改 url,同样也会渲染对应的组件,切换完毕后会把目标线路更新替换当前线路,这样就会作为下一次的路径切换的依据。
八、Vuex
Vuex 应用的核心就是 store(仓库)。“store”基本上就是一个容器,它包含着你的应用中大部分的状态 (state)。Vuex 和单纯的全局对象有以下两点不同:
1.Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
2.你不能直接改变 store 中的状态。改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化,从而让我们能够实现一些工具帮助我们更好地了解我们的应用。
通过定义和隔离状态管理中的各种概念并强制遵守一定的规则,我们的代码将会变得更结构化且易维护。
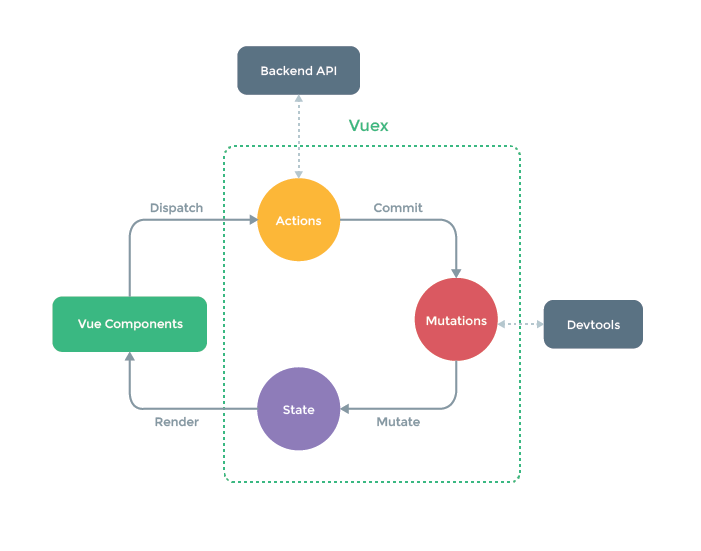
Vuex 初始化
- 安装
import Vuex from ‘vuex’ 的时候,实际上引用的是一个对象
1 | export default { |
1 | export function install (_Vue) { |
1 | export default function (Vue) { |
applyMixin 就是这个 export default function,它还兼容了 Vue 1.0 的版本,这里我们只关注 Vue 2.0 以上版本的逻辑,它其实就全局混入了一个 beforeCreate 钩子函数,它的实现非常简单,就是把 options.store 保存在所有组件的 this.$store 中,这个 options.store 就是我们在实例化 Store 对象的实例,稍后我们会介绍,这也是为什么我们在组件中可以通过 this.$store 访问到这个实例。
- Store 实例化
1 | export default new Vuex.Store({ |
1 | export class Store { |
Store 的实例化过程拆成 3 个部分,分别是初始化模块,安装模块和初始化 store._vm
把一个大的 store 拆成一些 modules,整个 modules 是一个树型结构。每个 module 又分别定义了 state,getters,mutations、actions,我们也通过递归遍历模块的方式都完成了它们的初始化。为了 module 具有更高的封装度和复用性,还定义了 namespace 的概念。最后我们还定义了一个内部的 Vue 实例,用来建立 state 到 getters 的联系,并且可以在严格模式下监测 state 的变化是不是来自外部,确保改变 state 的唯一途径就是显式地提交 mutation。
API
数据获取
数据存储
语法糖
mapState
mapGetters
mapMutations
mapActions
动态更新模块